第十一课 - 数据抽象中的效率与可读性
概要
本课将深入讨论数据抽象,体会设计数据结构时的权衡 (trade-off) — 高效率与可读性。
抽象数据类型 — 表 (table)
抽象数据类型表所规定的协议包含以下协议:
make — 创建新的表
put! key value — 往表中插入键值对,若有重复键则覆盖值
get key — 从表里检索该键对应的值
这便是一个表的抽象数据类型,它对具体的实现没有任何规定,只规定了接口行为。
实现1:Association List — List of Lists
如果要存储下面这张简单的表:
| x | 15 |
|---|---|
| y | 20 |
在 scheme 中我们可以用 list of lists 来表示:
> (list (list 'x 15) (list 'y 20))
((x 15) (y 20))
其内部结构如下图所示:
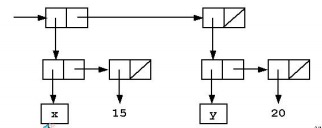
为了实现上文规定的协议,我们需要一些辅助操作 (operations)
; 以健查值
(define (find-assoc key alist)
(cond
((null? alist) #f)
((equal? key (caar alist)) (cadar alist))
(else (find-assoc key (cdr alist)))))
; 插入键值对
(define (add-assoc key val alist)
(cons (list key val) alist))
定义了以上两个操作我们就实现了表的基本功能,接着我们需要:
constructor — 表的构造器,即协议中的 make
information hiding — 隐藏背后依赖的 Scheme 的抽象数据类型 list
; Data Directed Programming
; table tag
(define table1-tag 'table1)
; constructor
(define (make-table1) (cons table1-tag nil))
; get
(define (table1-get tbl key)
(find-assoc key (cdr tbl)))
; put!
(define (table1-put! tbl key val)
(set-cdr! tbl (add-assoc key val (cdr tbl))))
问题1:如何判断 Table1 是表抽象数据类型的实现
你可能会想到的原因:
它有一个 type tag
它有一个 constructor
它有 mutators 和 accessors
但它们都不是根本原因。根本原因在对用户的抽象隔离,用户并不了解接口背后的实现。而 type tag、constructor、mutators 以及 accessors 是做到抽象隔离的必要组件:
type tag: 利用类型标签可以防止非 ADT 中的函数误操作
constructor: 在构造时隐藏了背后实现
mutators、accessors: 在操作时隐藏了背后实现
小结:
Association List 结构可以用来表示表的抽象数据类型
数据抽象技术 (constructors、accessors、mutators、type tag) 是支撑 information hiding 的基础
Information hiding 是模块化的必要条件
模块化是软件工程的核心
Opaque type names denote information hiding (理解意思但是不好翻译,暂时保留原话)
实现2:Hash Tables
利用 Association List 实现的表有很高的插入键值对效率 — O(1),但它的读取效率较差 — O(n),如果我们的使用过程有非常多的读取操作,则我们优化的方向就是换一种读取效率较高的实现。
Hash Table 的实现将基于 Scheme 的另一个抽象数据类型 — vector,它规定的接口协议如下:
make-vector
a vector with size locations; each initially contains value
number, A -> vector<A>
vector-ref
whatever is stored at that index of v (error if index >= size of v)
vector<A>, number -> A
vector-set!
stores val at that index of v (error if index >= size of v)
vector<A>, number, A -> undef
于是可以开始实现 Hash Table
; type tag
(define t2-tag 'table2)
; constructor
(define (make-table2 size hashfunc)
(let ((buckets (make-vector size nil)))
(list t2-tag size hashfunc buckets)))
; accessors
(define (size-of tbl) (cadr tbl))
(define (hashfunc-of tbl) (caddr tbl))
(define (buckets-of tbl) (cadddr tbl))
;; get
(define (table2-get tbl key)
(let ((index
((hashfunc-of tbl) key (size-of tbl))))
(find-assoc key
(vector-ref (buckets-of tbl) index))))
; mutators
;; put!
(define (table2-put! tbl key val)
(let ((index
((hashfunc-of tbl) key (size-of tbl)))
(buckets (buckets-of tbl)))
(vector-set! buckets index
(add-assoc key val
(vector-ref buckets index)))))
注意到,Association List 与 Hash Table 实现的 Table ADT 协议一模一样,可以无缝衔接,抽象对用户隔离。
问题:Table1 和 Table2 哪个更好?
答案:具体情况具体分析
对比一下二者的实现:
Table1:
make O(1)
put! O(1)
get O(n)
Table2:
make O(n)
put! O(1), 需要计算 hashfunc
get O(1 + k),需要计算 hashfunc (k 为 bucket 的大小)
在 get 操作极少且表规模较小的时候 Table1 更好。
在大部分时候 Table2 都更好,但前提是
要准确预测所需 vector 的大小
要选择合适的 hashfunc,使得 key 被均匀地分布